An extended power loss for my primary Proxmox 8 cluster, while I was remote, took half of my cluster nodes out of commission into an unbootable state. This unbootable half of the cluster would not show up on the network after the power came back even with manual physical rebooting. The other half would boot up and show on the network. All the nodes had a second problem that they would not open a PVE WebUI Console Shell or show any output on any of the video output ports for either the Nvidia PCIe GPU or the Intel iGPU. So I have to figure out what looks to be a set of overlapping issues and clean up this mess. There were several lessons learned and re-learned along the way.
First, I need a “crash cart” to recover these to a bootable state. What is a “crash cart”, well that is usually a rolling cart found in a data center that you roll up to a broken server. They typically include some sort of serial terminal and/or a monitor, keyboard and mouse with a lot of connectors and adapters to hook up to random port for the equipment you are fixing. Mine includes adapters for VGA, DVI, DisplayPort, HDMI and both USB and PS/2 keyboard and mice. I’ve even thrown in a spare known good Nvidia K600 video card for troubleshooting graphic cards. A trusty and up to date Ventoy Bootable USB is sitting on there as well. I have a laptop that I could use for a serial terminal if we get to that point but I was hoping I didn’t need it since those are mostly for network equipment.

Here is my quickly thrown together trash can crash cart (TC3) for this adventure.
Figuring out what was wrong took several steps, a couple blind alleys along with most of an evening, and into wee early morning.
This mess came about after I took the above mentioned power hit for my primary cluster location after a series of bad thunderstorms while I was remote. My homelab UPS only covers primary network services not my entire six node cluster. I have some plans to mitigate some of this but not this year. To add to the complexity, in the last month or two, I upgraded the Proxmox cluster remotely to the latest Proxmox which included major kernel updates. Proxmox went from 8.0 to 8.1 late last year and I pushed forward to 8.2 with several minor updates this year. That took me from my initial Linux kernel 6.2 to 6.5 and recently 6.8. Somewhere along the line, I lost my access to the Proxmox webui shell (console) access on the boxes and something broke the video output.
My first step was to just try using ssh into the boxes that had booted to the network and check for errors in the bootlogs. I did not see anything out of the ordinary in the logs but absolutely none of the video ports (VGA/DVI/DisplayPort) would start a usable session with a monitor plugged into it. Whatever this was, also impacted getting a webui console shell session as well for these boxes. I finally lost patience and was ready to pull the Nvidia Quadro P620 PCIe card but thought maybe I should just disable the Nvidia Nouveau Kernel Module and work from that direction looking at logs. Historically, you had to blacklist the Nouveau kernel module when setting up the Nvidia drivers. This was not the case but what I did find was something unexpected which was the Nouveau nvidiafb module was blacklisted.
Here is the dump from lspci for the working system. I have an Intel HD 2000 integrated GPU (iGPU) and the Nvidia Quadro P620 GPU shown on the PCI bus.
root@kovacs:~# lspci -k | grep -EA3 'VGA|3D|Display'
00:02.0 VGA compatible controller: Intel Corporation 2nd Generation Core Processor Family Integrated Graphics Controller (rev 09)
DeviceName: Onboard IGD
Subsystem: Dell 2nd Generation Core Processor Family Integrated Graphics Controller
Kernel driver in use: i915
--
01:00.0 VGA compatible controller: NVIDIA Corporation GP107GL [Quadro P620] (rev a1)
Subsystem: NVIDIA Corporation GP107GL [Quadro P620]
Kernel driver in use: nouveau
Kernel modules: nvidiafb, nouveau
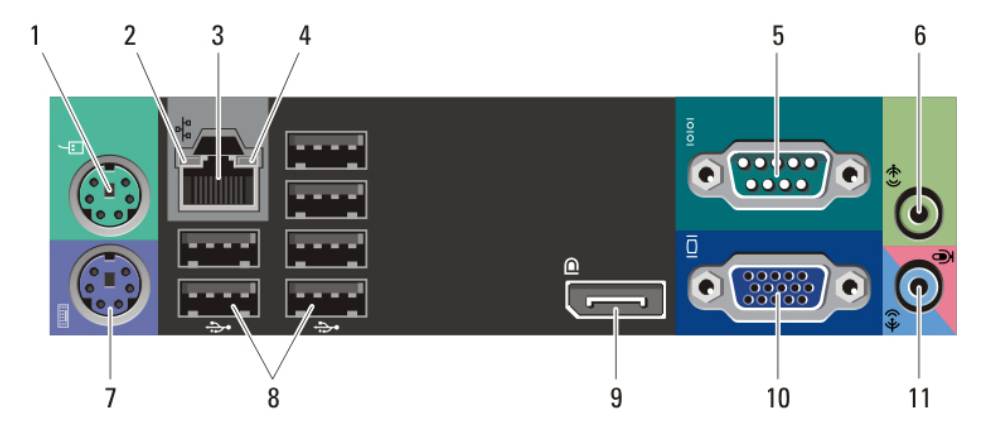
| 1. mouse connector |
2. link integrity light |
3. network connector |
| 4. network activity light |
5. serial connector |
6. line-out connector |
| 7. keyboard connector |
8. USB 2.0 connectors (6) |
9. DisplayPort connector |
| 10. VGA connector |
11. line-in/microphone connector |
|
Here is a picture of the back of the Dell Optiplex 990 nodes. We have four cards loaded up with three PCIe cards and a PCI card. Those are from left to right:
| Slot# |
Bus |
Card Description |
| 1. |
PCIe 8x |
Nvidia Quadro P620 GPU |
| 2. |
PCIe 1x |
Powered USB 3.0 four port card |
| 3. |
PCI |
Dual Port 1Gbps NIC |
| 4. |
PCIe 4x |
Dual Port 1Gbps NIC |

So you can see I have several monitor ports. There are four mini-DisplayPort on the Nvidia card, and both a VGA and full-sized DisplayPort on the motherboard.
The next problem was something that I should have caught faster. I had an AIMOS HDMI 8-port KVM Switch in the middle of the connections to each of the boxes. For whatever reason, this KVM was not syncing the video signal on the Nvidia P620 mini-displayport (along with the K600s) and was not getting the keyboard and mouse to work either but without the monitor working I could not see that. This whole thing was part of a setup with a PiKVM and a display duplicator project that stalled out with some odd failures. The base KVM had been rock solid earlier so I considered it a solid piece of working infrastructure. As a random check, I pulled both out of the mix for one host and got an error from the iGPU VGA and DisplayPort on the motherboard which was my first video signal that worked. I have never been so happy to see error screens…
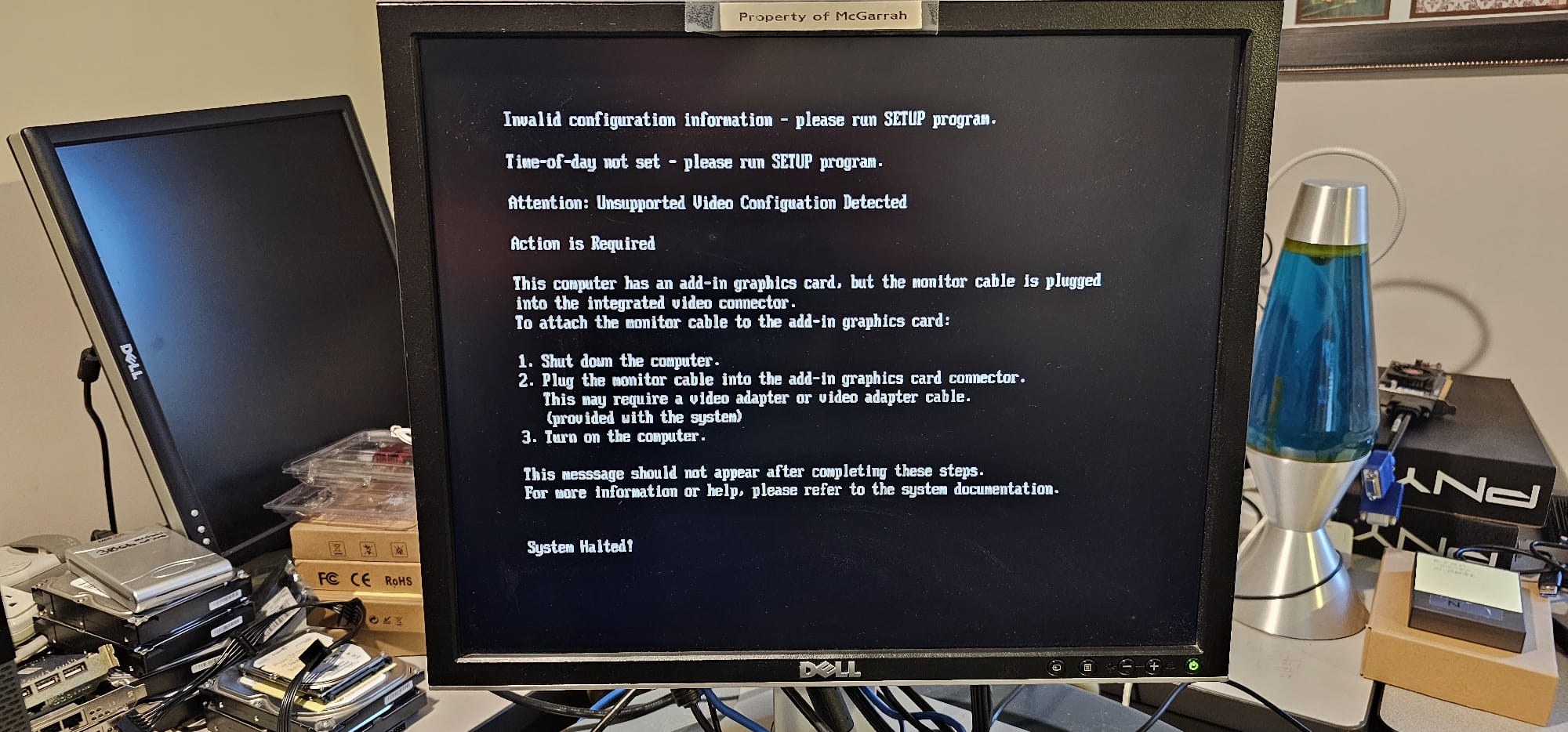 |
 |
| VGA Test |
DisplayPort Test |
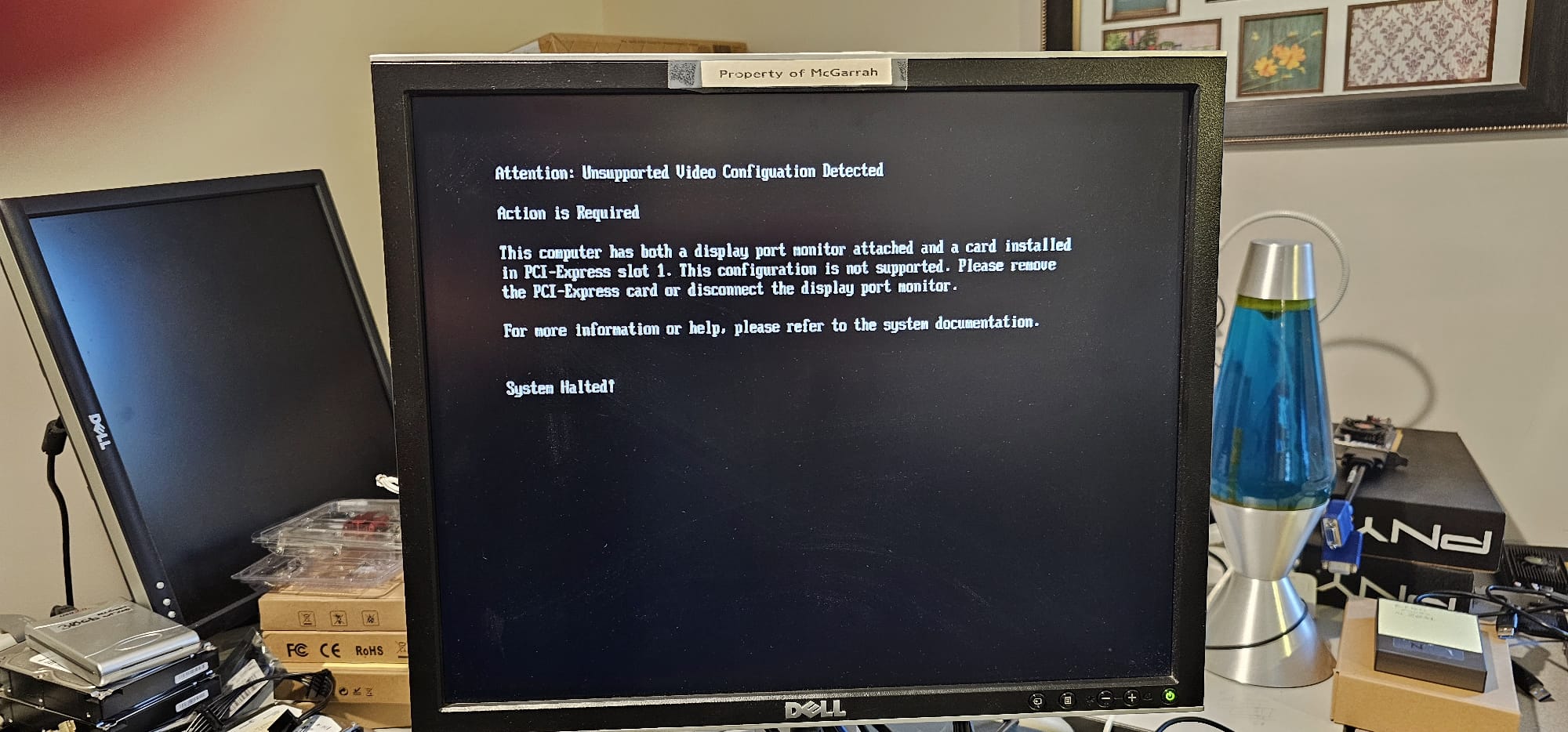
I also had a second issue that conflated with the above KVM issue. The issue was that the full-sized DisplayPort connector on the motherboard of the first system I was testing was bad, and of course that is the one I used in my first tests. It looks like I, or someone before me, pulled the DisplayPort cable out hard without releasing the connector. This is part of why I kept not getting results on that first system from the motherboard video tests from that DisplayPort. Another issues that seemed to indicate a broader issue was related to Nvidia was that the Nvidia Quadro K600 GPUs had the same issues as the Nvidia Quadro P620. So I assumed it was something Nvidia related that was broken once I removed the KVM.
With the above figured out, I switched back to using the first mini-DisplayPort from the Nvidia GPU directly hooked to crash cart monitor with an adapter from DVI to mini-DisplayPort and got a clean signal after a reboot. With this, I could now see errors that looked related to BIOS settings being cleared or missing date/time values that usually indicate a bad BIOS CMOS battery. So the below error was actually a good thing.
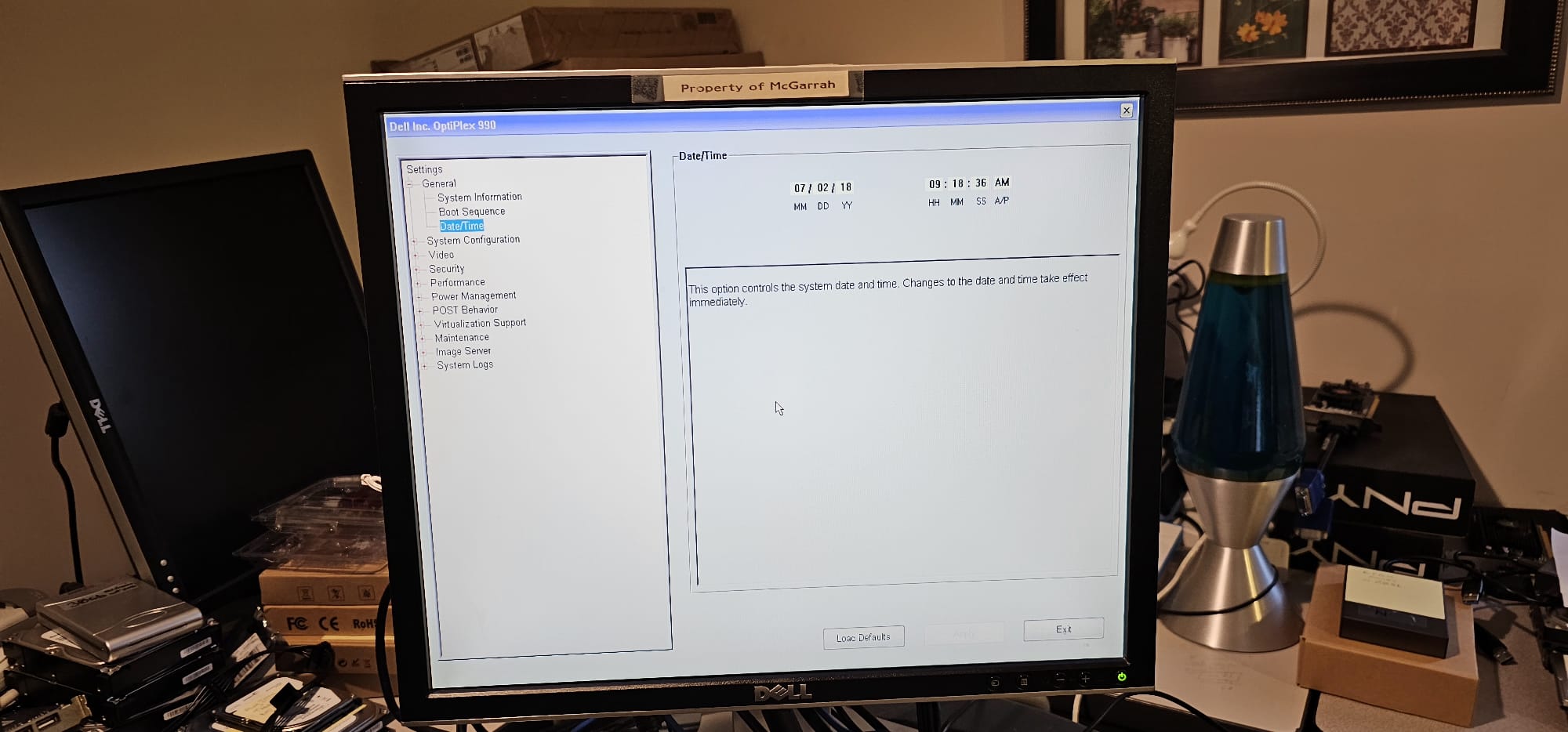
I had a path forward now and some hope things would come back up. My first step was to swap out the coin CR2032 battery on each system that had bad BIOS settings or missing date/time. Next step was to reset the BIOS configurations and date/time on each of those systems.
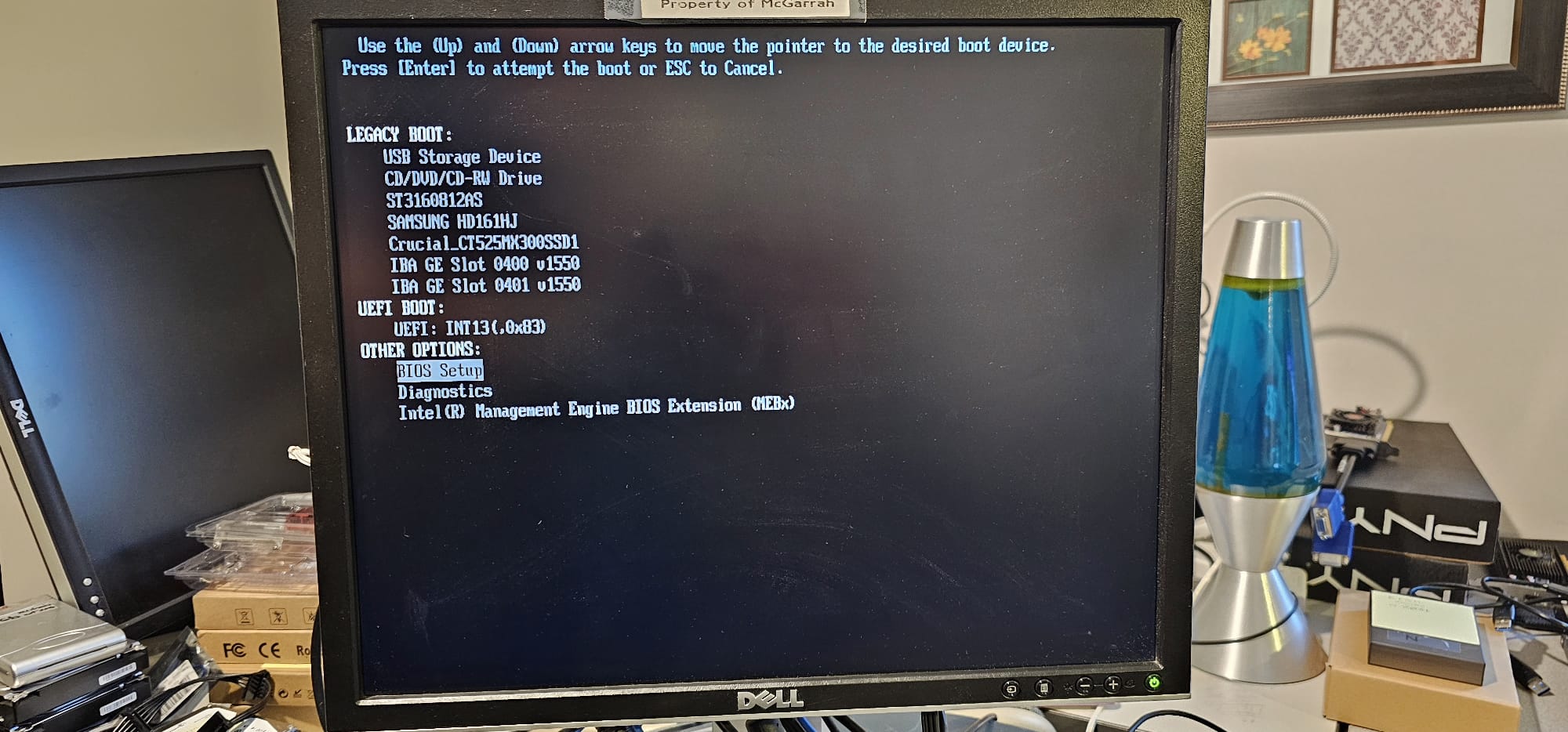
While going thru the BIOS settings, I remembered something I saw in my rummaging around on Google and Reddit, a reference to enabling both the PCIe GPU and integrated GPU (iGPU) on older Dell OptiPlex systems.
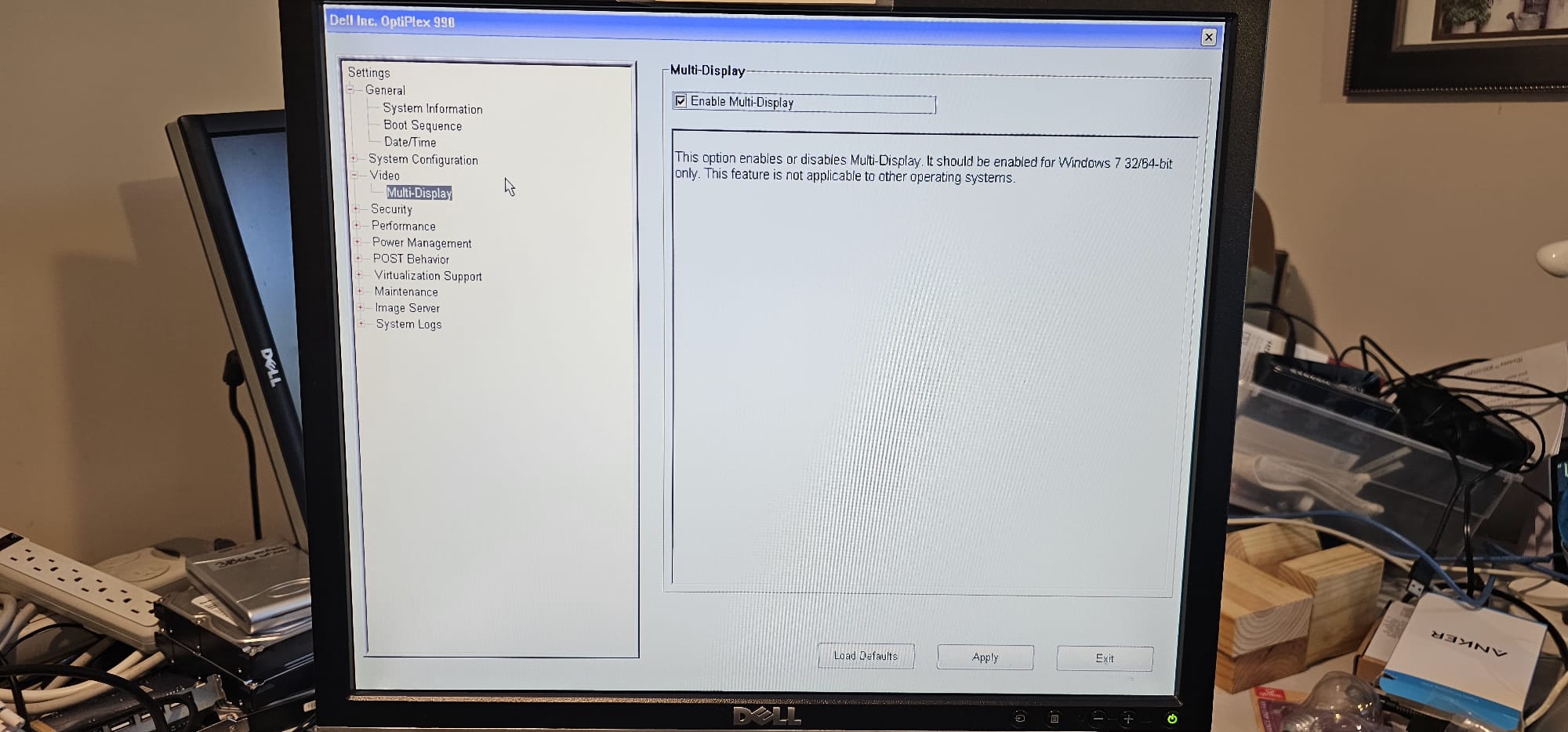
Enabling this “Multi-Display” option in the BIOS, made it so that I could use the built-in motherboard iGPU as well as the Nvidia GPU at the same time. This opens up options for me to fully virtualize the Nvidia GPU and making it available only for a VM or LXC while maintaining a console session. Keeping the option of a boot up session for cases like the BIOS issue I hit are important to me long term.

My next to last issue, was a bad CAT5 network cable on my SAN Network Switch that intermittantly fails when jiggled. I have been chasing this issue and finally found it while moving around the cluster nodes when I saw one of the ports go and stay dark occasionally. This has been immensely frustrating to find and should improve my Ceph stability. To add to the mess, I have a rats nest of cabling hooking this all together which is painful when I have to dig into the hardware.

So to summarize, I had some borderline CMOS batteries in a couple hosts that left some BIOS settings cleared to their defaults, or left with inconsistent and/or just bad BIOS settings. Some of those bad settings could have been from the batteries or just me fumbling them at some point. A Nvidia FrameBuffer driver issues on a kernel upgrade likely caused some of the confusion. A bad SAN network cable took awhile to find as just general instability in Ceph. The bad motherboard DisplayPort connector almost had me scream at the ceiling when I found it as it stalled progress for almost an hour leaving me confused. I am still not sure about the bad luck with the KVM EDID settings after the power hit and reboot. I just left the KVM unplugged to diagnose later. All of which culminated in a very late evening digging apart the mess the extended power outage left behind.
What have I learned or re-learned? Upgrades of the Linux Kernel should be respected as major events and do not do them remote and test everything after the upgrade. I thought I had mitigated those risks during upgrades with my Dell Wyse 3040 Proxmox Cluster but obviously not for everything. Another lesson is that old hardware needs better documentation for quirks, as you find them, like the bad DisplayPort, CMOS battery replacement dates, and odd events like Ceph network timeouts/errors.
Epilog: The nodes in the cluster are Mini-Tower Dell Optiplex 990 with Nvidia Quadro P620 with disabled Intel HD 2000 iGPU. Finding the “Multi-Display” option in the BIOS during this ordeal was a real find that will enable more features as I move forward with using the NVidia GPUs. The loss of the KVM is painful but I’ll circle back at it and see about getting it to work with the PiKVM as an IP KVM combo for multiple remote systems.
About the Author:
Michael McGarrah is a Cloud Architect with 25+ years in enterprise infrastructure, machine learning, and system administration. He holds an M.S. in Computer Science (AI/ML) from Georgia Tech and a B.S. in Computer Science from NC State University, and is currently pursuing an Executive MBA at UNC Wilmington.
LinkedIn ·
GitHub ·
ORCID ·
Google Scholar ·
Resume