Performance tuning Ceph in a homelab environment presents unique challenges, especially when running on USB storage and constrained hardware. After dealing with performance issues during cluster rebalancing and OSD expansion, I’ve learned valuable lessons about mClock configuration, IOPS optimization, and the realities of USB 3.0 storage performance.
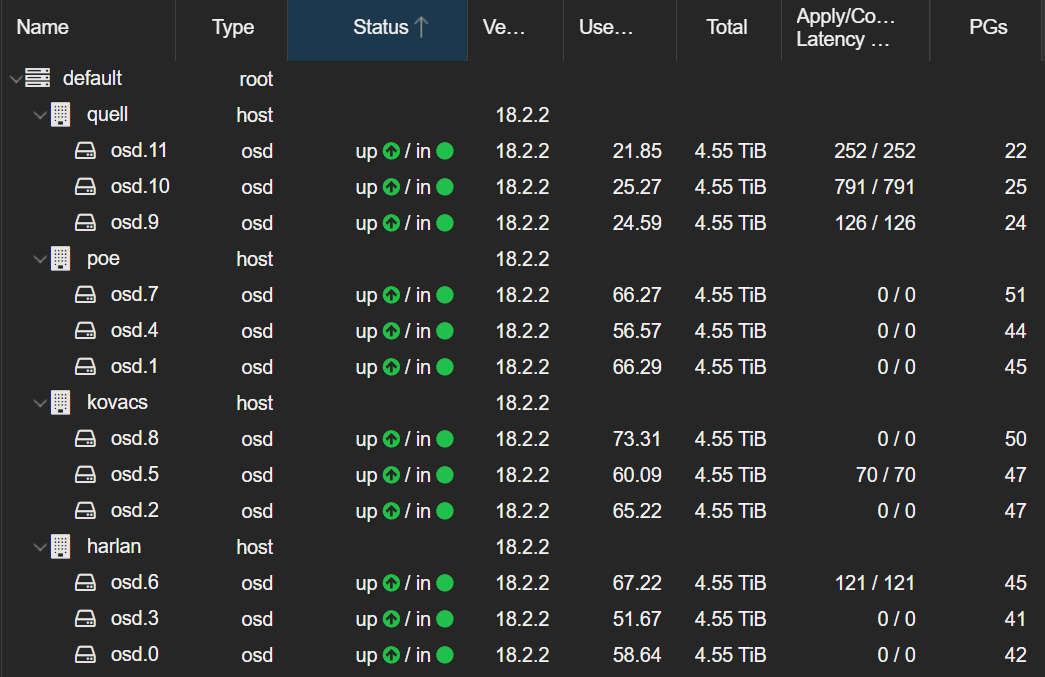
I encountered two interconnected performance issues while expanding my cluster from three to four nodes:
- Inconsistent mClock IOPS settings: Some OSDs had missing or incorrect
osd_mclock_max_capacity_iops_hdd values
- Major cluster rebalancing: Moving from 3 nodes with 4 OSDs each to 4 nodes with 3 OSDs each
The rebalancing process was taking much longer than expected, and I suspected the inconsistent mClock settings were contributing to the performance bottleneck.
Understanding mClock in Ceph
The mClock Config Reference explains how Ceph implements the dmClock algorithm for scheduling storage activities.
What is mClock?
mClock is Ceph’s quality of service (QoS) scheduler that manages IOPS allocation between different operation types:
- Client operations: User-initiated reads and writes
- Background recovery: Data movement during rebalancing
- Scrubbing: Data integrity checks
- Snap trimming: Snapshot cleanup operations
mClock Profiles
Rather than manually tuning individual parameters, Ceph provides three predefined profiles:
balanced (default): Equal priority for client and background operationshigh_client_ops: Prioritizes client operations over background taskshigh_recovery_ops: Prioritizes recovery operations for faster rebalancing
Diagnosing mClock Configuration Issues
Check your current mClock settings:
root@harlan:~# ceph config dump | grep mclock
WHO MASK LEVEL OPTION VALUE RO
osd.0 basic osd_mclock_max_capacity_iops_hdd 86.136079
osd.1 basic osd_mclock_max_capacity_iops_hdd 87.204995
osd.4 basic osd_mclock_max_capacity_iops_hdd 89.152214
The Problem: Missing IOPS Values
In my case, some OSDs were missing the osd_mclock_max_capacity_iops_hdd setting entirely. This happened when:
- Adding new OSDs to an existing cluster
- Ceph’s automatic capacity detection failed
- Hardware changes affected the initial benchmarking
My test cluster showed significantly different IOPS values:
Test Cluster (Dell Wyse 3040s):
root@pve1:~# ceph config dump | grep mclock
osd.0 basic osd_mclock_max_capacity_iops_hdd 194.542100
osd.1 basic osd_mclock_max_capacity_iops_hdd 192.359779
osd.2 basic osd_mclock_max_capacity_iops_hdd 205.899236
After Adding New USB Drives:
osd.3 basic osd_mclock_max_capacity_iops_hdd 339.211615
osd.5 basic osd_mclock_max_capacity_iops_hdd 340.816549
osd.6 basic osd_mclock_max_capacity_iops_hdd 326.667183
The newer USB drives (OSDs 3, 5, 6) showed significantly higher IOPS capacity, likely due to:
- Better USB 3.0 interface utilization
- Newer drive firmware
- Different USB controller chipsets
Use Ceph’s built-in benchmarking to test individual OSD performance:
root@harlan:~# ceph tell osd.0 bench 12288000 4096 4194304 100
{
"bytes_written": 12288000,
"blocksize": 4096,
"elapsed_sec": 2.868101647,
"bytes_per_sec": 4284366.9828972416,
"iops": 1045.9880329338969
}
Performance Comparison:
Main Cluster (Good Performance):
- IOPS: 1,045
- Throughput: 4.28 MB/s
- Latency: Low and consistent
Test Cluster (Constrained Performance):
root@pve1:~# ceph tell osd.0 bench 12288000 4096 4194304 100
{
"bytes_written": 12288000,
"blocksize": 4096,
"elapsed_sec": 18.758997973,
"bytes_per_sec": 655045.64890332799,
"iops": 159.92325412678906
}
- IOPS: 159 (6.5x slower)
- Throughput: 655 KB/s (6.5x slower)
- Latency: Significantly higher
USB 3.0 Specifications:
- USB 3.0: 5 Gbps theoretical (625 MB/s)
- USB 3.1: 10 Gbps theoretical (1.25 GB/s)
- USB 3.2: 20 Gbps theoretical (2.5 GB/s)
Real-World Performance:
- Protocol overhead reduces actual throughput by 15-20%
- USB-to-SATA bridge limitations
- Drive-specific performance characteristics
- USB controller quality and implementation
Why 10-16 MiB/s Transfer Rates?
Several factors limit USB drive performance in Ceph:
- Random I/O patterns: Ceph generates lots of small, random writes
- USB protocol overhead: Especially problematic for small block sizes
- Drive caching: USB drives often have limited write caches
- Concurrent operations: Multiple OSDs competing for USB bandwidth
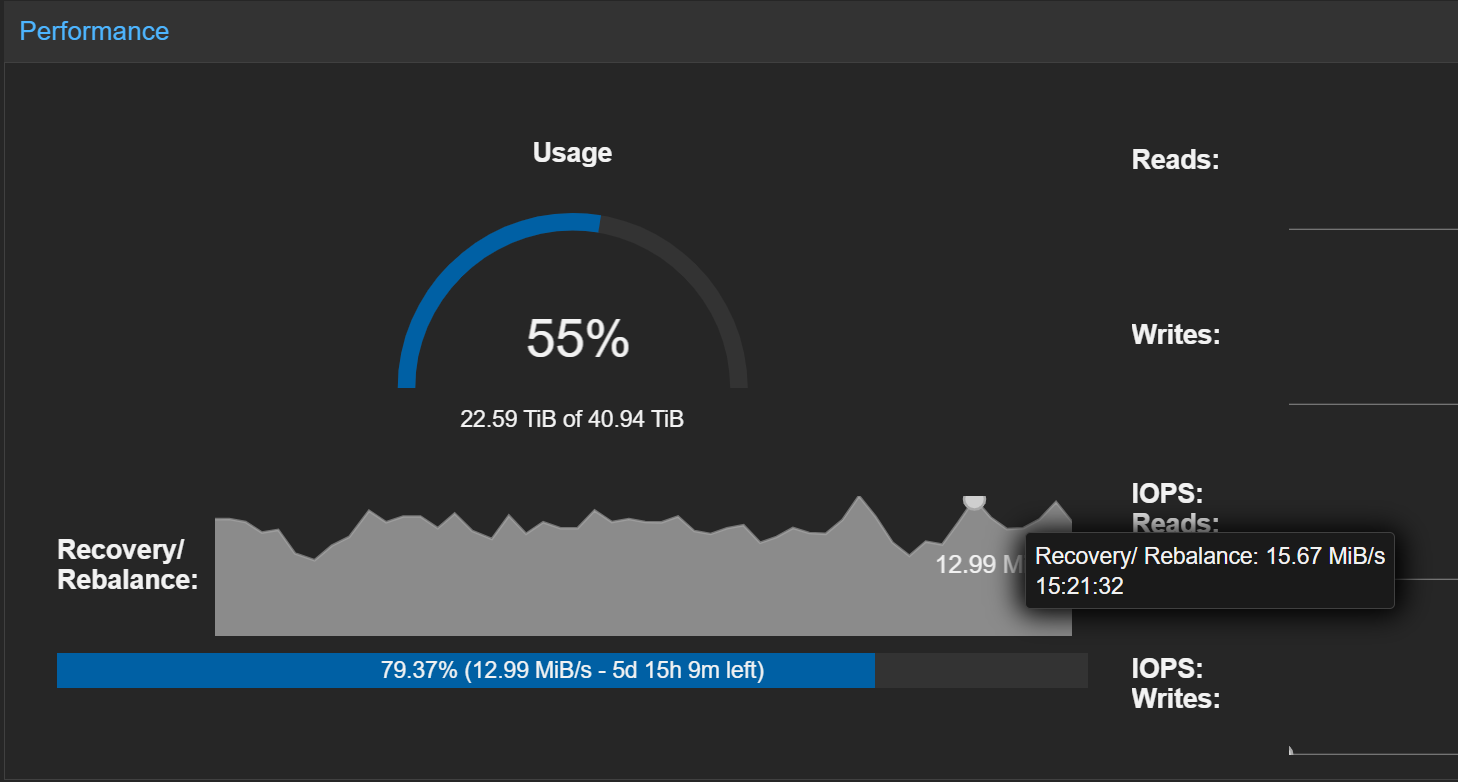
Optimizing mClock for Rebalancing
Using mClock Profiles
Instead of manually adjusting individual parameters, use mClock profiles:
# Enable high recovery operations during rebalancing
ceph config set global osd_mclock_profile high_recovery_ops
# Monitor rebalancing progress
ceph status
# Return to balanced profile after completion
ceph config set global osd_mclock_profile balanced
Manual IOPS Configuration
If automatic detection fails, manually set IOPS values:
# Set IOPS for specific OSD
ceph config set osd.X osd_mclock_max_capacity_iops_hdd 200
# Set globally for all HDDs
ceph config set global osd_mclock_max_capacity_iops_hdd 200
Real-time I/O Statistics
Monitor cluster I/O in real-time:
root@harlan:~# ceph iostat -p 5
+-------------------------+-------------------------+-------------------------+-------------------------+-------------------------+-------------------------+
| Read | Write | Total | Read IOPS | Write IOPS | Total IOPS |
+-------------------------+-------------------------+-------------------------+-------------------------+-------------------------+-------------------------+
| 0 B/s | 0 B/s | 0 B/s | 0 | 0 | 0 |
During active rebalancing, you should see significant write activity as data moves between OSDs.
# Check cluster performance
ceph status
ceph osd perf
# Monitor individual OSD performance
ceph daemon osd.X perf dump
# Check rebalancing progress
ceph pg dump | grep active+clean
Lessons Learned
What Worked
- mClock profiles are better than manual tuning: Use
high_recovery_ops during rebalancing
- Consistent hardware helps: Try to use similar USB drives across OSDs
- Monitor during changes: Watch performance metrics when adding OSDs
- Patience with USB storage: Accept that USB drives will be slower than enterprise SSDs
What Didn’t Work
- Ignoring mClock settings: Missing IOPS values significantly impact performance
- Mixing drive types: Different USB drives create performance imbalances
- Expecting SSD performance: USB drives have inherent limitations
- USB interface limitations: Even USB 3.0 struggles with Ceph’s I/O patterns
- Network bandwidth: 1Gbps networking can become a bottleneck
- CPU constraints: Dell Wyse 3040s have limited processing power
- Memory pressure: 2GB RAM is tight for Ceph operations
Recommendations for Homelab Ceph
Hardware Considerations
- Use consistent USB drives: Same model/manufacturer when possible
- Prefer USB 3.1/3.2: Better performance than USB 3.0
- Consider USB-C interfaces: Often have better controllers
- Monitor drive health: USB drives can fail without warning
Configuration Best Practices
- Set appropriate mClock profiles: Use
high_recovery_ops during maintenance
- Monitor IOPS settings: Ensure all OSDs have proper capacity values
- Plan rebalancing windows: USB storage makes operations slower
- Use optimized scrubbing schedules: Reduce wear on USB drives
- Sequential throughput: 20-40 MB/s per USB drive
- Random IOPS: 100-300 IOPS per USB drive
- Rebalancing time: Plan for 2-3x longer than SSD-based clusters
- Recovery operations: Expect slower rebuild times after failures
Conclusion
Optimizing Ceph performance in a homelab requires understanding the limitations of your hardware and adjusting expectations accordingly. While USB storage will never match enterprise SSD performance, proper mClock configuration and realistic expectations can deliver a functional distributed storage system.
Key takeaways:
- Use mClock profiles instead of manual parameter tuning
- Monitor and correct missing IOPS capacity values
- Accept USB storage limitations but optimize within those constraints
- Plan maintenance windows appropriately for slower operations
The performance may not be enterprise-grade, but for homelab use cases like media storage, backup, and learning Ceph administration, USB-based clusters can provide valuable experience with distributed storage concepts.
For more Ceph optimization guidance, see my articles on Ceph nearfull management and ProxMox 8.2.4 Upgrade on Dell Wyse 3040s.
References
About the Author:
Michael McGarrah is a Cloud Architect with 25+ years in enterprise infrastructure, machine learning, and system administration. He holds an M.S. in Computer Science (AI/ML) from Georgia Tech and a B.S. in Computer Science from NC State University, and is currently pursuing an Executive MBA at UNC Wilmington.
LinkedIn ·
GitHub ·
ORCID ·
Google Scholar ·
Resume